
1.为什么是卷积?
在深度学习中,卷积主要用作升维和局部特征提取,有如下优点:
1. 卷积操作参数较小,所有输入共享卷积核的参数
2. 卷积具有平移不变性,确保在特征位置变化的情况下依然可以识别
3. 卷积核小的特性决定了它关注的是局部特征
2.参数
pytorch官方的conv2d类有如下参数:
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)in_channels 指的是输入通道数,out_channels 指输出通道数,均为 int 类型
kernel_size 为卷积核的大小,为 int 类型或者 tuple(元组)类型,如果输入为 int(比如 3),Conv2d 类会自动处理其为元组(如 (3, 3),表示卷积核的大小为 3*3),当然也可以用元组设定卷积核大小不为正方形(如(1, 2) 的输入表示卷积核大小为 1*2)
stride 指步长,默认为 1,即卷积核在每次移动时均移动 1 个像素点(包括纵向移动)
padding 指填充,默认为 0 即无填充,填充要搭配填充模式使用,一般都是填充为 0 即 padding_mode='zeros'
bias 是偏置,用于在卷积后增加一个偏置再输出,一般都开启
device 是设备,有 GPU 的情况下可以在这里选择将模型跑到 GPU 上
dtype 是数据类型,这里特指张量的数据类型,比如 float32(双精),float16(单精),float8(半精)等
以上是一些常用的参数量,下面是一般都用不到的参数:
dilation 指计算时卷积核元素之间的距离,默认为 1,使用大于 1 的 dilation 时又称膨胀卷积
groups 指输入输出之间的分组,默认为 1,大于 1 时为分组卷积,并且 groups 要求能被输入输出通道数整除,假设 groups 为 2,输入输出会被分为两组分别进行卷积,最终再整合到一起
3.参数的图形化解释
常言道“数缺形时少直观”,下面使用官方的图对几个参数做一下解释(但是官方图都有点问题,我贴的这几个图的卷积核都是 3*3 的才对)
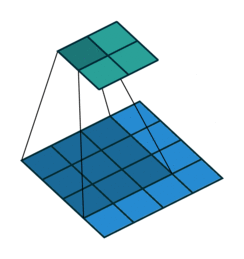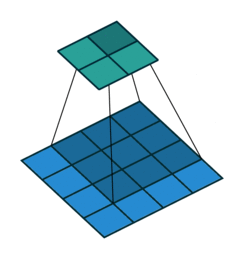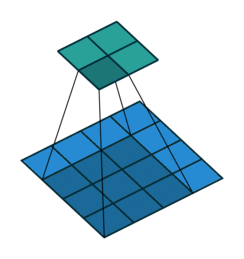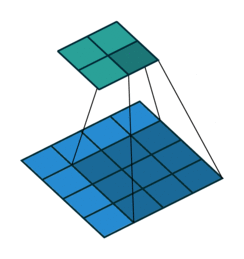
图 1 默认填充步长(即 padding = 0, stride=1)
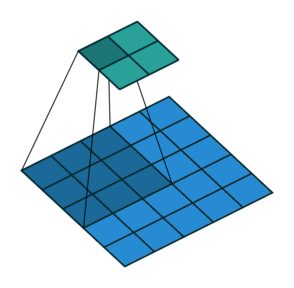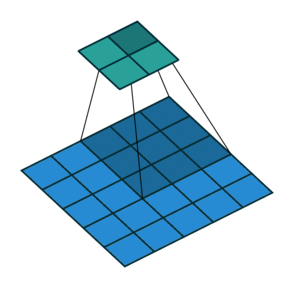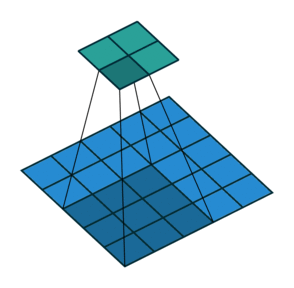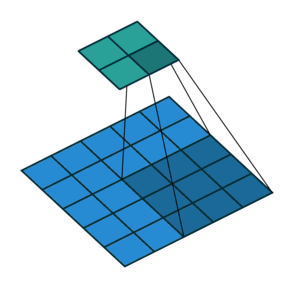
图 2 默认填充步长为 2(即 padding = 0, stride=2)
很明显,相比于图 1 都默认的情况来说,步长的作用其实就是规定卷积核中心的移动像素点个数,这不仅包括横向也包括纵向的移动,但是值得一提的是,stride 也可以是一个元组,这样就可以达到横向纵向移动步长不同的效果
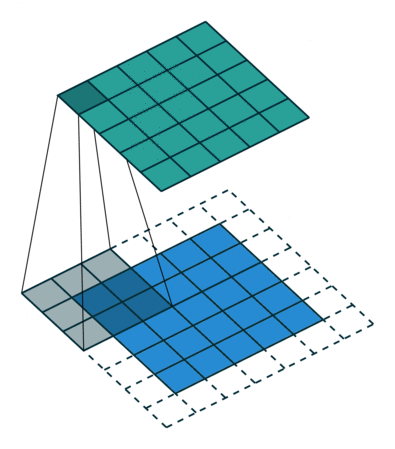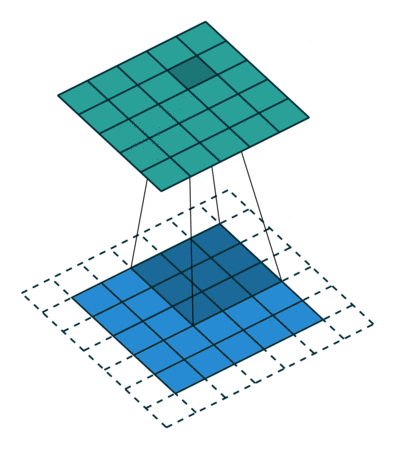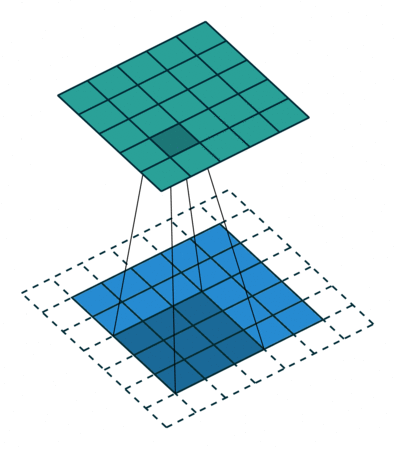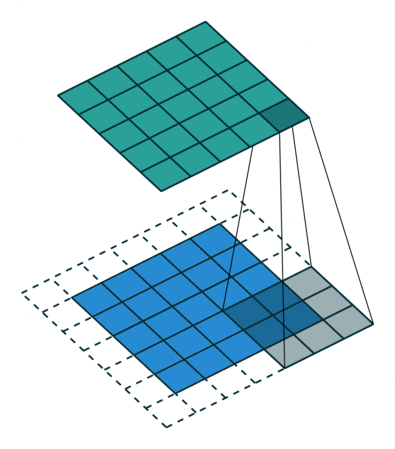
图 3 填充 1 默认步长(即 padding = 1, stride=1)
相较于图 1 来说,图 3 周围多了一圈空的像素点,这就是填充,前面也说了填充要搭配填充模式来食用,一般来说填充模式都采用 zeros(即补 0)的方式,因此说图 3 周围是一圈空像素点。在 padding 为 1 的时候是在四周各添加一行(或一列)的像素点,相应的 padding 为 2 的时候是在四周各添加两行(或两列)的像素点。填充本身的目的是希望能用卷积核的中心覆盖每个像素点保证运算时不遗漏输入边缘的细节。
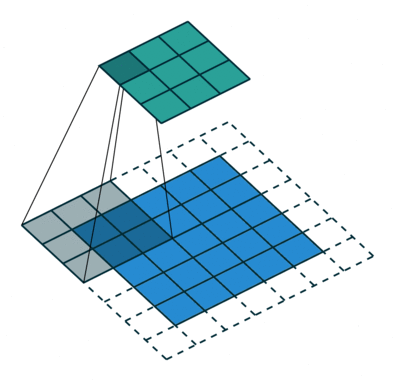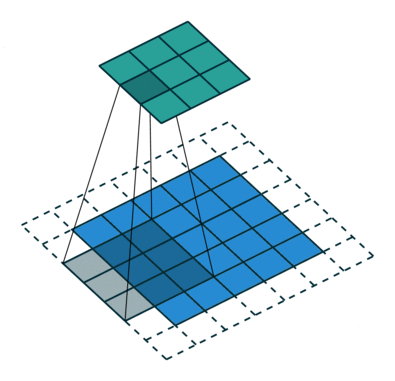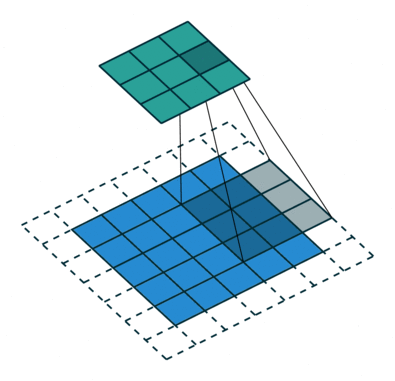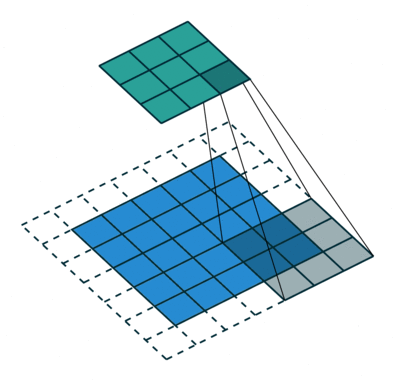
图 4
根据以上的解读,请各位思考图 4 的填充值和步长(答案见评论区)
膨胀卷积
既然已经放图了自然不能放过介绍膨胀卷积的好机会,图 5 就是膨胀卷积 dilation 为 2 的情况
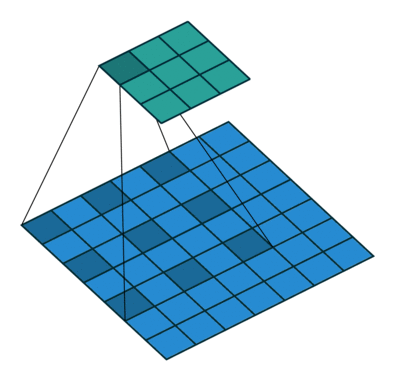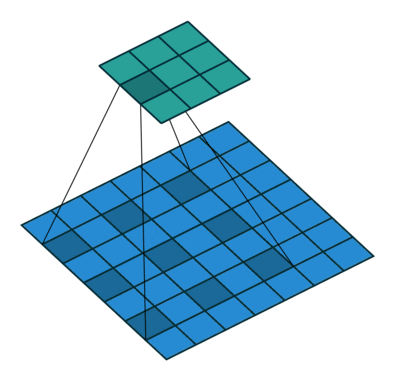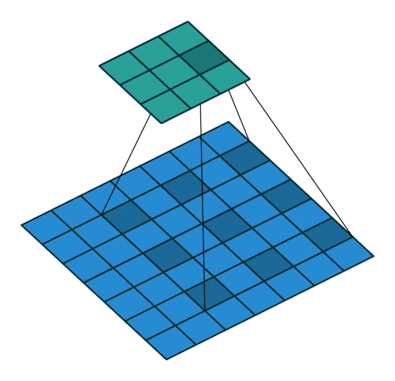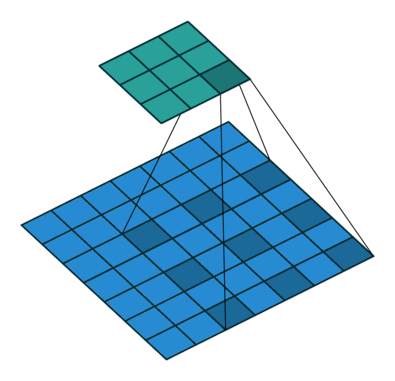
图 5 dilation 为 2
这里非常反直觉的是,卷积核的像素点之间的间距是 dilation-1,同样的 dilation 也支持元组输入,分别表示横向和纵向的卷积核间距
根据我的理解,dilation 主要用于减少计算量,并提升原始输入的还原能力,因为更少的卷积可以更好地保留原始输入的细节
膨胀卷积这样的卷积方式一般用于图像修复、图像分割和语音合成这样的领域上
4.一些细节上的小知识
卷积核数量
前面所有的介绍中都只表现出一个卷积核,但是实际上卷积核的数量是由输出通道数决定的,比如我输出通道数为 6,则有 6 个卷积核分别跟输入进行了卷积运算,并且卷积核之间并不一定是相同的,很有可能每个卷积核都是不同的。
这时候就容易有疑惑,那输入通道为 3 输出通道为 6 的时候为什么不是两个卷积核而是 6 个卷积核呢?
这时就不得不提运算中卷积核的真正工作方式了:假设输入为一个 3 通道的数据,那么卷积核实际上并不是 3*3,而是 3*3*3 的,它在卷积时是一个立方体的卷积核在 RGB 三色图的数据中做卷积的,每次得到的仅仅是一个输出通道,因此要想得到 6 通道的数据是需要 6 个卷积核的。相应的灰度图只有一个输入通道,其卷积核为 1*3*3;升维后的数据假设有 6 个通道,那么在对其做卷积时其卷积核就是 6*3*3 的。
5.可视化表示
这步演示我使用 CIFAR10 数据集,构建一个最简化的模型来演示卷积的实际效果,图 1 是原始图像,图 2 是卷积后的结果,这里取一个 batch 做演示:

图 1 原始图像

图 2 卷积后的结果
下面是测试代码:
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10(root="./CIFAR10", train=False, download=True, transform=torchvision.transforms.ToTensor())
data_loader = DataLoader(dataset=test_data, batch_size=64)
class Example(nn.Module):
def __init__(self):
super(Example, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
output = self.conv1(x)
return output
example = Example()
step = 0
writer = SummaryWriter('./conv2d_logs')
for data in data_loader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = example(imgs)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
writer.close()
默认评论
Halo系统提供的评论