
1.主流AI目前实现的功能
目前国内综合类 AI 中,功能最全的非豆包莫属,本文以豆包中的功能为例去剖析目前市面上 AI 实现的功能中较为底层的实现方式。
目前豆包实现的功能纷繁复杂,主要的功能有音视频通话、AI 绘图、拍照答疑、录音纪要、图生图、翻译等。根据火山方舟大模型的模型广场,字节目前对外提供服务的 AI 模型也根据这些功能分为深度思考、文本生成、视频生成、图片生成和语音模型。也就是说,除这些 AI 模型外,其他的功能都是在此基础上添加各种交互功能得到的。
2.AI各种功能的底层实现
在上述功能中,最复杂、同时功能也最齐全的非音视频通话莫属。
2.1音视频通话
在目前实现的音视频通话中,其关键步骤可以拆分为以下几点:
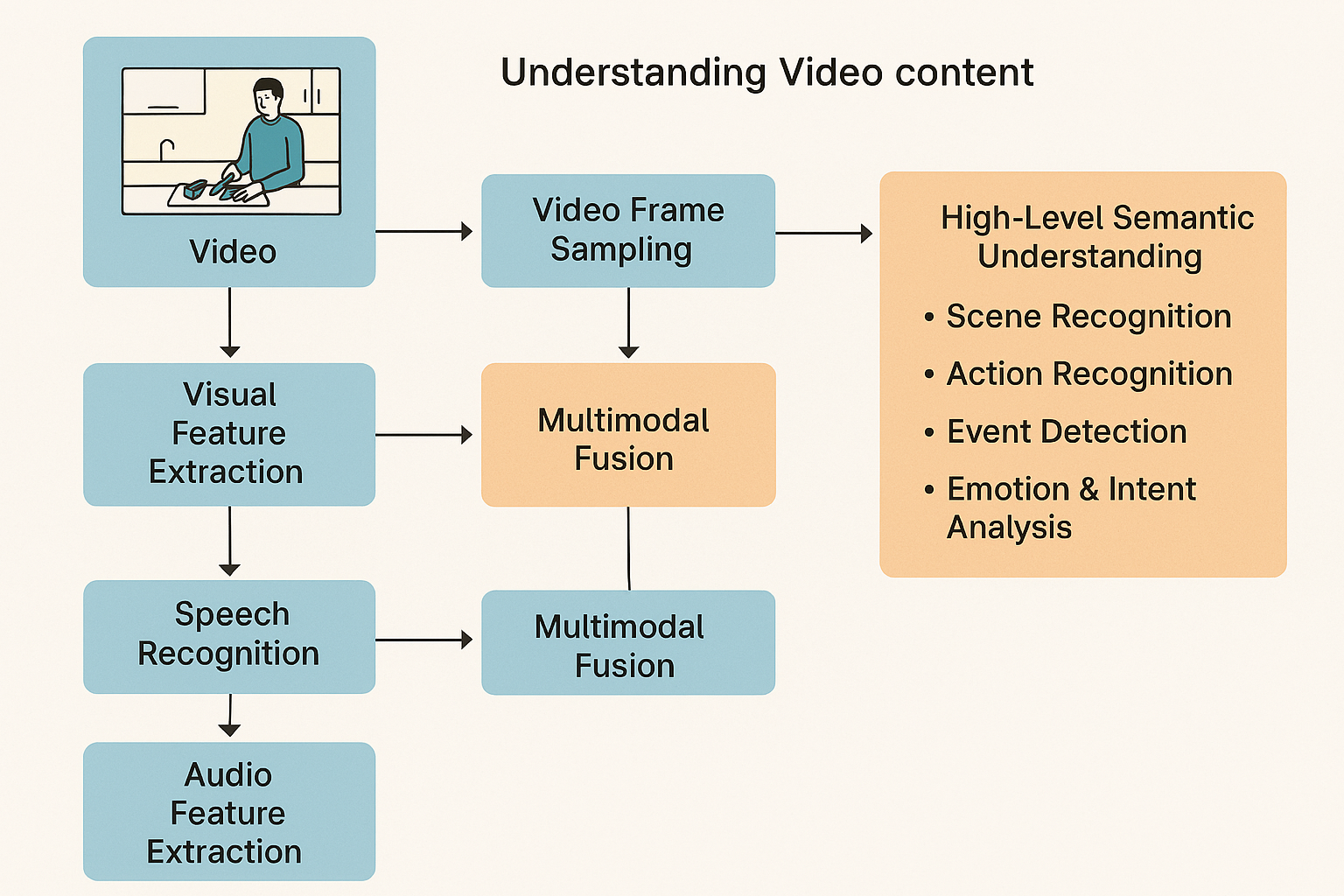
帧采样:从目前的技术实现与必要性来说,AI 理解视频内容既不需要也没必要去实时抓取每一帧的图像数据,只需要间隔一定的时间提取关键帧用于 AI 分析。从技术实现来说,关键帧提取可以减少很多算力开销,从必要性来说关键帧足以代替这一段时间间隔内的信息表达。
采集到的关键帧会被传输到 AI 服务器中进行分析,主要包含视觉信息提取和运动信息建模。其中视觉信息提取的实现方式主要是 CNN(卷积神经网络)模型或 transformer 模型提取图像特征,比如问豆包视频中出现的东西是什么,就需要经过 CNN 或者 transformer 模型分类。运动信息建模会用到 3D 卷积神经网络、光流分析和时序 Transformer 模型捕捉动作和动态变化,比如豆包分析视频中的人物动作就需要依靠此功能。利用这两个功能,AI 就可以理解视频的主要内容。
除了图像处理外,音视频通话需要额外处理音频信息,目前主流的 AI 都使用 ASR 模型作为自己的语音识别模型;有些 AI 还会使用特殊训练的声学模型分析用户的情绪语调。
在单独处理完音视频信息后,还需要对处理后的信息做融合分析,即多模态融合(其实模态就是数据的不同形式)。这一步主要包含:
1. 时间同步:将分析得到的音视频信息在时间轴上进行对齐,确保信息能正确对应。
2. 跨模态建模:使用多模态的 transformer 模型将音视频信息融合起来便于理解,如 OpenAI 的 CLIP 模型直接把文字,还有图片转换成向量,然后通过模态对齐的方式,让文字向量和图片向量产生关联,然后可以进行相似度计算,即通过文字搜图片 (text-to-image),通过图片搜文字 (image-to-text),通过文字搜文字 (text-to-text),通过图片搜图片 (image-to-image)。
3. 上下文理解:跨模态建模得到的融合数据用于 AI 理解用户意图和行为。
在此时,AI 就可以根据用户输入(得到的音视频数据)针对性地进行回复。
2.2AI绘图
目前 AI 绘图主要包含文生图、图生图两大类,他们用的都是 VAE 或 U-Net 神经网络(扩散模型)。
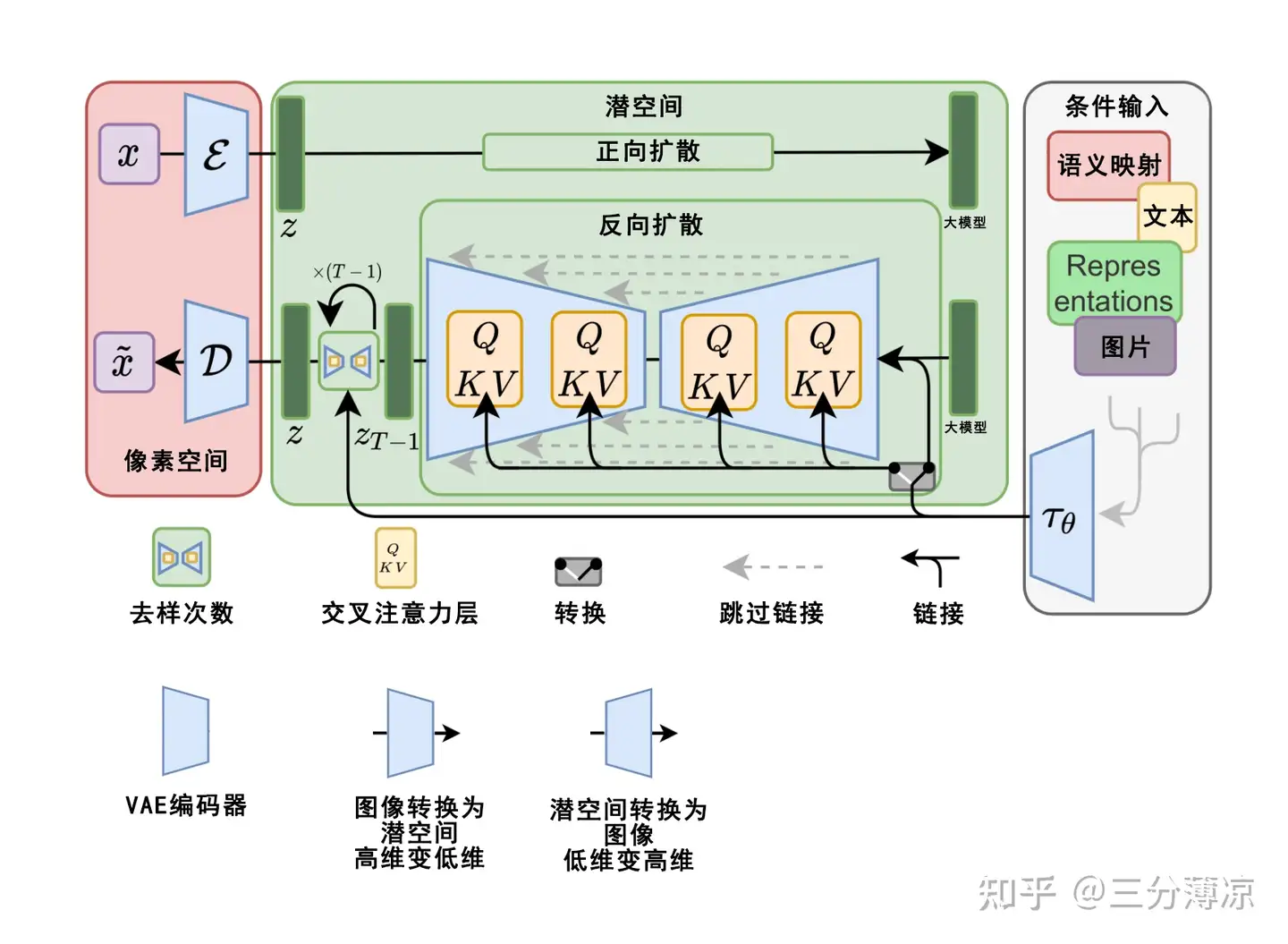
其原理说起来较为简单,将一个图像不停加噪模糊,就可以得到一张充满噪点的图像,如果给这个图像做标注,那么它将可以用来训练模型,这对应的就是模型中的正向扩散,反过来使用噪点和用户输入的关键词,不停反向迭代(噪点图像和预测噪点相减)就可以得到一个清晰的、符合输入关键词的图像,这对应的就是反向扩散。
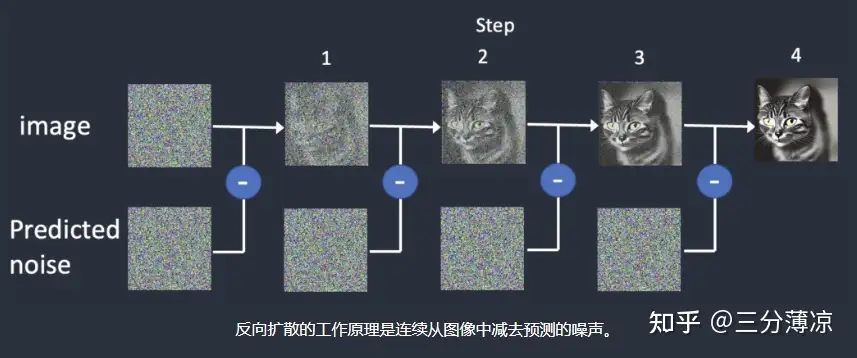
现在较火的 stable-diffusion 模型、DALLE 模型都是这样的实现方式。
图生图的原理也与之类似,只是多了一步图像输入。这里输入的图像就需要用正向扩散进行处理,获得一个输入图像的纯噪声图像。而这个纯噪声图像就是后续处理用到的噪声图像,根据用户提供的关键词对这个纯噪声图像进行相应的反向扩散就可以得到新的图生图的图像结果。
2.3拍照答疑
拍照答疑相比之前的功能来说会更简单一些,其中主要涉及三部分,即 OCR 模型的文字识别、语义理解和逻辑拆解。
OCR 模型主要可以拆成预处理图片、切割字符、识别字符、恢复版面和后处理文字五个部分,常见的各种证件识别、名片识别、车牌识别、QQ 和微信的提取文字功能等都涉及 OCR 技术。

将题目转化为 OCR 识别到的结构化文本后,豆包会根据题目内容识别其中的考点、题目类型等(语义理解),进行推理(类似深度思考),梳理得到解题步骤。
2.4录音纪要
录音纪要相比之前的内容更简单,主要流程就是将语音转化为文字(如 STT 模型),之后使用 AI 模型对转化得到的文字进行总结梳理,生成结构化的总结输出。
3.豆包手机
豆包手机的很多功能实现底层都是上述的流程,但是在信息获取的方式上有所不同。
3.1屏幕信息获取
与传统的截屏或者录屏的获取方式不同,豆包手机用的是安卓系统底层的 GPU 渲染的图形缓冲区,即在图形还没呈现在你的手机上之前,豆包已经将数据取走了,其好处是可以绕开一些屏幕读取限制,但是豆包手机也增加了 secure 层的检测,在遇到诸如手机银行这些高隐私性的 APP 时,豆包将会向服务器回传一个空的占位图来代替之前传输的屏幕图像。
3.2屏幕模拟点击
与手机上常见的自动化操作软件(如自动精灵)不同,豆包手机的屏幕模拟点击是直接靠注入输入事件来实现的,其操作要底层很多,而且其操作位置是一块虚拟屏幕(这个就是从前面拿的 GPU 图形缓冲区的数据生成的),这样即使用户在使用屏幕做别的事情也不影响 AI 对手机的操作。
3.3本地与云端的工作分工
豆包手机和其他个人终端一样,在 AI 这种高算力场景下功能孱弱,采用的工作逻辑也和其他终端类似;即本地负责一些基础的执行任务,剩余的思考、任务规划等高算力需求的工作都是交给云端来做。
3.4个人思考
豆包手机并不是第一个做这种 Agent 的产品,在这之前就有不少手机厂商做过类似的工作,如 OPPO 的小布、荣耀的 YoYo;但是豆包手机是第一个做的如此激进的产品,它划时代地开创了强泛化 Agent 在生活中的应用,将人从互联网错综复杂的世界中解放了出来,使之前不断消费人注意力的体系被撼动,因此豆包手机遭到针对一事可想而知。一方面豆包手机的行为已经越过了制定规则的各个厂商的权限底线,另一方面其本身巨大的生产力的进步性也使保守派们惴惴不安。
从历史的经验来看,从唯物辩证来看,豆包手机这类强泛化的 Agent 迟早会成为主流产品,但是在这之前的新旧碰撞与不断斗争都将持续;AI 从出现至今,都不断地在冲击旧有的世界体系,它在不断地改变我们的生产方式、生活方式。但是在这些之前,人们也许还需要更多时间去了解、接受这些新的体系下的新产品,需要在不断地斗争中完善新的体系、新的规则,逐步地形成一套足以取代现有生产方式的成熟的 Agent 产品。
4.AI在这些功能中的作用
AI 在这些功能中起到的作用比较多样,但是至少有一个是不变的,即其对话与思考推理的主体模型(在海量数据上预训练,具备通用的表示和生成能力的模型)是固定的,以豆包为例,无论是在音视频通话还是拍照答疑会议纪要这些功能中,其核心的对话和思考推理的主模型都是 doubao-seed 模型;除此之外,为了实现多样化的功能,AI 也需要一些其他模型来实现特定的功能,下表是一些常见的模型类型。
对于像豆包这样的 AI 工具来说,大语言模型是他们最核心的部分,就像人的大脑,负责思考和表达;而视觉模型等则像人的其他功能,分别负责自己领域的一些工作。

默认评论
Halo系统提供的评论